Le processus de production de la base de données comporte trois briques principales de traitements
(1) L'intégration des données : réception, contrôles, mises au format
(2) Redressements : synchronisation (correction de la non-réponse totale)
(3) Codification des causes de décès
Avant intégration dans la base de données de travail, des contrôles de cohérence sont réalisés sur toutes les données structurées (sexe, date de décès, date de naissance, communes et case cochées...)des certificats (papier uniquement, les contrôles sur les certificats électroniques se font au moment de la collecte) en comparant les informations du certificat entre elles (date de décès supérieure ou égale à la date de naissance par exemple) et à celles du B7 lorsqu'il est reçu. Si une incohérence est détectée, des corrections sont réalisées soit de façon automatique, soit manuellement au travers d'une application avec interface permettant de comparer l’image du certificat à sa retranscription numérique et au B7.
Il s'agit d'un alignement avec les données de décès issues de l'Etat civil, produites et maintenues par l'Insee.
L'objectif est de compléter les trous de collecte (décès dont le volet médical n'a pas été reçu par l'Inserm) par des observations avec valeurs manquantes (cause inconnue) et de supprimer les doublons (deux volets médicaux reçus pour le même décès). Il y a aussi un objectif de correction et d'enrichissement des variables socio-démographiques.
En pratique, la méthode combine une identification au Répertoire national d'identification des personnes physiques et des appariements sur les variables communes entre le volet médical du certificat de décès et le BEC avis de décès (date et lieux de décès et de naissance, sexe et numéro d'acte), avec relâche successive des contraintes. Ces appariements garantissent la confidentialité des données traitées car il n'y a pas de partage d'information sur les causes de décès d'un côté, et les noms des défuns de l'autre. Ces alignements se font tous les mois en date de réception, puis chaque année en date d'événement.
Un texte médical riche, polysémique, à transformer en un langage statistique commun
Le constat d'un décès relevant d'un diagnostic médical, le médecin qui en prend la responsabilité est libre dans sa rédaction, sans pré-remplissage. C’est d’une recommandation de l'OMS. La spécificité des causes de décès provient bien de cette information textuelle riche en termes et faiblement structurée qu’il faut transformer en un langage statistique commun.
Coder les causes de décès dans la CIM a deux finalités distinctes
Il s'agit de déterminer dans le texte écrit par le médecin les entités nosologiques pour leur affecter un code de la nomenclature la classification internationale des maladies (CIM) et déterminer la cause initiale du décès dès que définie dans la CIM.
Pour satisfaire ce double objectif, la classification internationale des maladies décrit en complément de la nomenclature (c’est-à-dire les codes) un ensemble de règles de codage, rassemblées dans un volume 2, le « guide de référence ». Ce manuel d’instruction au codage outille le codeur : une douzaine de règles appliquées sur la séquence causale selon un algorithme précis permet de déterminer la cause initiale du décès, d’une façon systématique, tout en corrigeant des erreurs ou des incohérences possibles dans la chaîne causale déclarée ou encore en privilégiant certaines pathologies à suivre car d’intérêt de santé publique.
Ce besoin d'homogénéité pour assurer la comparabilité de la statistique dans le temps et l'espace a motivé l'automatisation du codage. Le caractère systématique du raisonnement et la présence de règles précises décrites dans la CIM font de l'exercice un candidat idéal.
Pour en savoir + les statistiques de A à Z
Le système expert Iris principal outil de codage des causes de décès assure l'homogénéité du codage et la comparabilité internationale
Iris facilite beaucoup la mise en œuvre de la Classification internationale des maladies (CIM) dont la complexité augmente sans cesse et permet d'améliorer la comparabilité internationale des données produites. Les systèmes experts de codage des causes de décès sont utilisés en France depuis 2000, à l'occasion de la mise en œuvre de la CIM 10. Styx, développé en France, puis Iris à partir de 2012, s'appuient sur le modèle international du certificat de décès et intègrent les règles du volume 2 de la CIM 10 sous forme de relations entre codes CIM, rassemblées dans des « tables de décisions » maintenues internationalement. Elles suivent les mises à jour annuelles officielles de l'OMS. Le système expert de codage Iris comportent deux étapes :
-Coder en CIM 10 toutes les “causes”, c’est-à-dire maladies, traumatismes, séquelles, que le médecin mentionne
dans le certificat avec des termes médicaux. Cette première étape dépend de la langue. Après des standardisations du texte du certificat (synonymes, abréviations, termes non pertinents), il est mis en correspondance avec un dictionnaire contenant 157 000 expressions, pour lesquelles chaque terme est associé à un ou plusieurs codes CIM 10.
- Appliquer les règles de la CIM10 pour déterminer parmi ces “causes”, la cause initiale de décès, à savoir la cause
qui a enclenché le processus (causal) conduisant au décès (dû à, dû à …). Ceci se fait à l'aide des tables de décision, et du Multicausal and Unicausal Selection Engine (MUSE, moteur de sélection de cause initiale et de cause multiple) d'Iris. Cette étape prend aussi en compte les circonstances de décès, l'âge et le sexe du défunt.
Pour en savoir +
- Consulter le site de l'Iris Institute.
- Courrier des statistiques
Batch à la réception et codage interactif par l'équipe de codage
Le système expert Iris est lancé en batch à la réception pour un codage automatique. Il est aussi mobilisé en tant qu'outil de codage assisté pour un codage manuel en interactif par les experts-codeurs du CépiDc. L'équipe de codage est composée de codeurs-nosologistes spécialistes de la CIM. Leur travail s'organise en fonction de leur niveau d'expertise (codeurs, nosologistes et experts).
Pour en savoir + les statistiques de A à Z
Une troisième technique, basée sur l'intelligence artificielle (IA)
Entraîné sur l'historique des certificats déjà codés, des réseaux de neurones profonds (RNP)vont transformer l'enchaînement des termes médicaux décrivant le processus morbide (séquence d'entrée) en un enchaînement de codes de la CIM et proposer une cause initiale (séquence de sortie). Ces RNP sont utilisés pour prédire la séquence des codes et pour déterminer la cause initiale de certains certificats. Il y a plusieurs stratégies : soit utiliser le code directement prédit par le modèle, soit appliquer le système expert Iris-muse sur la séquence des causes prédites par le modèle pour en déduire la cause initiale. Les précautions mises en œuvre pour guider le choix de la procédure s'appuient sur le code des bonnes pratiques de la statistique européenne. Les architectures des réseaux ont été choisies pour leur simplicité. Leur entraînement et leur inférence peuvent être réalisés sur des infrastructures conventionnelles. Il a été décidé de ne pas s'appuyer sur des modèles pré-entraînés, ni très complexes, pour garder entièrement le contrôle de la procédure statistique, depuis les données d'entraînement jusqu'aux modèles. On garantit le respect de la confidentialité des données, la réplicabilité et transparence de la procédure et on limite les risques de biais dans un souci d'impartialité et d'objectivité. Enfin, l'évaluation statistique qui permet de contrôler les modèles est inhérente à ces procédures. Leurs erreurs peuvent être mesurées, analysées, documentées.
Pour en savoir +
- ZAMBETTA, Élisa, RAZAKAMANANA, Nirintsoa, ROBERT, Aude, CLANCHÉ, François, RIVERA, Cecilia, MARTIN, Diane, HEBBACHE, Zina, FLICOTEAUX, Rémi et COUDIN, Élise, 2023. Codage des causes de décès de 2018 et 2019 en CIM10 - Approche combinant deep learning, système expert et codage manuel ciblé. In : Document de travail du CépiDc No 2. [en ligne]. Septembre 2023.
- ZAMBETTA, Élisa, RAZAKAMANANA, Nirintsoa, ROBERT, Aude, CLANCHÉ, François, RIVERA, Cecilia, MARTIN, Diane, HEBBACHE, Zina, FLICOTEAUX, Rémi et COUDIN, Élise, 2024. Combining deep neural networks, a rule-based expert system and targeted manual coding for ICD-10 coding causes of death of French death certificates from 2018 to 2019. In : International Journal of Medical Informatics. Août 2024. Volume 188.
- Courrier des statistiques
Articuler les modes de codage et cibler l'expertise humaine
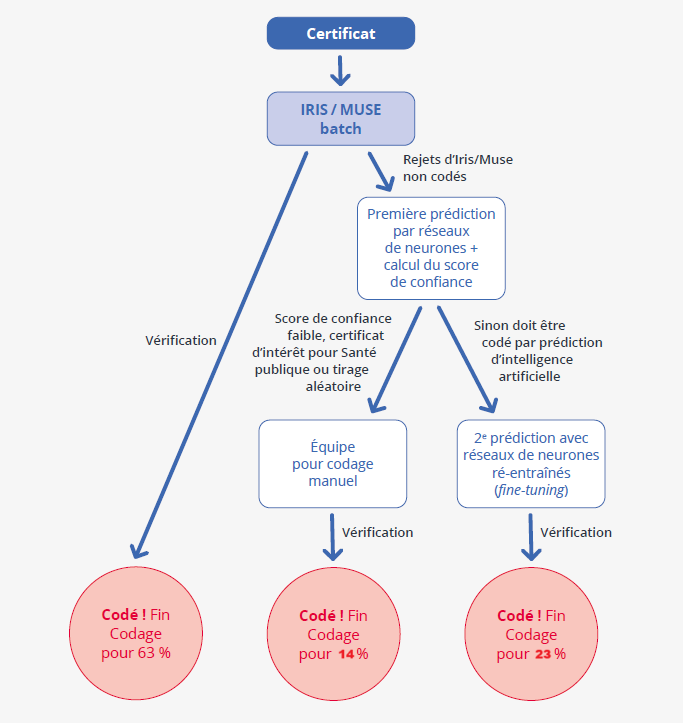
Les certificats qui ne sont pas codés entièrement automatiquement par batch vont être affectés soit à un codage manuel assisté, soit à un codage par prédiction de réseaux de neurones profonds, pour optimiser la qualité de la production, en respectant les principes suivants :
- par campagne, le volume de certificats pouvant être codés manuellement est fixé à l’avance, en fonction des ressources humaines disponibles dans l’équipe de codage, de façon à respecter les délais de diffusion de la base statistique (93 000 certificats en 2021) ;
- les situations pour lesquelles les prédictions des RNP sont moins vraisemblables, repérées sur la base d'un score de confiance modélisé et estimé pour chaque certificat, seront codées manuellement de façon ordonnée en commençant par les plus mauvaises. Il en sera de même pour certains cas d’intérêt pour la santé publique pour lesquels l'OMS requiert un suivi attentif : décès d’enfants en dessous d’un certain âge, morts maternelles, virus de l'immunodéficience humaine (VIH) ou syndrome d'immunodéficience acquise (SIDA) ;
-en complément, pour assurer l'entraînement et le contrôle réguliers des RNP, des échantillons tirés aléatoirement sont envoyés en reprise manuelle ;
-en fin de campagne, une partie de ces certificats codés manuellement, ainsi qu'une partie de ceux codés par batch automatique, sont utilisées pour ré-entrainer les RNP et obtenir la prédiction finale des certificats codés par RNP.
Ainsi, l'expertise humaine n'est plus mobilisée en bout de chaîne pour traiter les rejets du système de règles, mais dès le début pour alimenter les modèles et se concentrer sur les cas les plus complexes.
Vérifications
La dernière étape de codage consiste à vérifier manuellement des codages potentiellement improbables repérés à partir de règles déterministes.
Pour en savoir +
voir les rapports de production des causes de décès d'une année comme HEBBACHE, Zina, BOULET, Pierre, ROBERT, Aude, ZAMBETTA, Elisa, RAZAKAMANA, Daniel, COUDIN, Élise et MARTIN, Diane, 2024. Rapport de production : année de décès 2021. In : Document de travail du CépiDc. [en ligne]. Mars 2024. No 8. [Consulté le 6 novembre 2024].